Crawl là gì? hay bot công cụ tìm kiếm là một ngôn ngữ không hề xa lạ với người làm website và dân Marketing. Tuy nhiên, cách thức hoạt động của web spiders ra sao và có tầm ảnh hưởng như thế nào đến quá trình SEO không phải là điều mà ai cũng biết. Cùng Checknet tìm hiểu khái niệm Crawl là gì? và cách hoạt động của Crawl tại bài viết dưới đây.
Crawl là gì?
Khi nói đến SEO (Search Engine Optimization), bạn sẽ thường nghe đến thuật ngữ “Crawl.” Đây là một quá trình quan trọng trong việc thu thập thông tin từ các trang web trên Internet. Crawl đơn giản là việc bot của công cụ tìm kiếm đi qua các trang web để tìm và cập nhật thông tin mới nhất. Những bot này được gọi là “Web Crawlers” và còn được biết đến với tên gọi thú vị là “spiders.”

Web Crawl là gì?
Web Crawl, còn được gọi là “Web Crawling” hoặc “Spidering,” là quá trình tự động duyệt qua các trang web trên Internet để thu thập thông tin. Web Crawlers tự động theo dõi các liên kết từ trang này đến trang khác, tạo ra một bản sao của các trang đã duyệt và gửi thông tin này về cho công cụ tìm kiếm. Điều này giúp công cụ tìm kiếm cập nhật dữ liệu và đưa ra kết quả tìm kiếm chính xác cho người dùng.

Cách bot của công cụ tìm kiếm crawl website
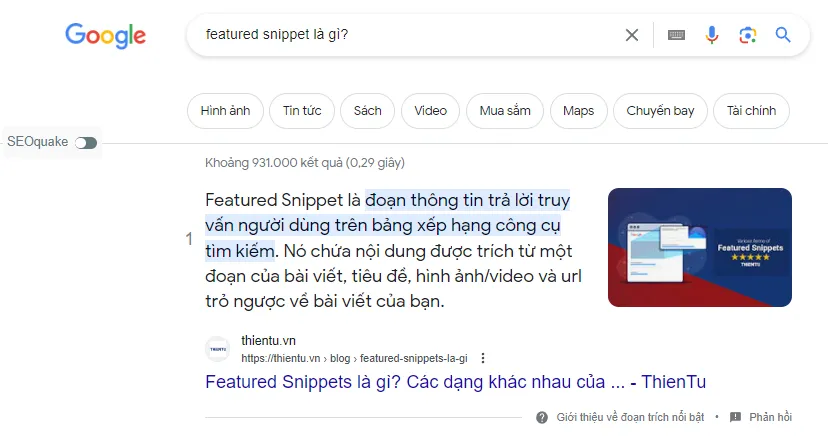
Quá trình crawl website bắt đầu bằng việc bot của công cụ tìm kiếm tìm kiếm một trang web và đọc nội dung trang. Sau đó, bot theo dõi tất cả các liên kết có trên trang và tiếp tục duyệt qua các trang khác. Quá trình này lặp đi lặp lại cho đến khi bot đã duyệt qua tất cả các trang web liên quan.
Một khi bot đã crawl hết các trang web, nó lưu trữ thông tin thu thập được trong cơ sở dữ liệu của công cụ tìm kiếm. Thông tin này sau đó được sử dụng để xác định sự phù hợp của trang web đối với các truy vấn tìm kiếm của người dùng.
Vì sao Web Crawlers được gọi là spiders
Web Crawlers được gọi là “spiders” bởi vì cách hoạt động của chúng giống như cách con nhện tạo ra mạng nhện. Mỗi sợi mạng nhện tạo ra một liên kết tới một trang web, và các liên kết này sẽ dẫn dắt con nhện tới các trang khác. Tương tự, Web Crawlers tạo ra một mạng lưới các liên kết giữa các trang web trên Internet bằng cách duyệt qua các trang và theo dõi các liên kết có trên chúng.
Những con “spider” này chạy tự động và không ngừng nghỉ, điều này cho phép các công cụ tìm kiếm luôn cập nhật dữ liệu và đảm bảo cung cấp kết quả tìm kiếm chính xác và nhanh chóng cho người dùng.
Những yếu tố làm ảnh hưởng Web Crawler
Khi bot của công cụ tìm kiếm crawl website, có một số yếu tố quan trọng làm ảnh hưởng đến quá trình này. Dưới đây là một số yếu tố quan trọng:
Domain
Tên miền của trang web cũng là một yếu tố quan trọng. Các trang web có tên miền uy tín và lâu đời thường được ưu tiên crawl hơn các trang web mới thành lập và không rõ nguồn gốc.
Internal Links
Liên kết nội bộ trong trang web cũng có tác động đến việc crawl. Các trang web có cấu trúc liên kết rõ ràng và dễ dàng điều hướng sẽ được crawl hiệu quả hơn.
XML Sitemap
XML Sitemap là một tệp tin chứa danh sách tất cả các trang trong trang web và thông tin liên quan. Các trang web có XML Sitemap sẽ được crawl dễ dàng hơn.
Backlinks
Backlinks, hay còn gọi là liên kết đến trang web từ các trang web khác, cũng là yếu tố quan trọng. Các trang web có nhiều backlinks từ các trang web uy tín sẽ có khả năng crawl cao hơn.
Canonical URL
Canonical URL được sử dụng để xác định trang chính thức của một nội dung khi có nhiều URL đồng nghĩa. Xác định rõ ràng Canonical URL sẽ giúp bot crawl chính xác trang chính của nội dung.
Duplicate Content
Nội dung trùng lặp trong trang web có thể làm cho bot lúng túng và không thể crawl hết các trang. Đảm bảo tránh việc có quá nhiều nội dung trùng lặp để crawl hiệu quả.
Meta Tag
Các thẻ Meta như Meta Title và Meta Description cũng ảnh hưởng đến việc crawl. Meta Title nên là tựa đề chính xác của trang và Meta Description cung cấp mô tả ngắn gọn về nội dung của trang.
Bots crawl website có nên được truy cập các thuộc tính website không?
Một câu hỏi thường gặp là liệu bots crawl website có nên được truy cập các thuộc tính website không?
Trong thực tế, điều này còn phụ thuộc vào mục đích của trang web và chính sách của chủ sở hữu trang. Trong nhiều trường hợp, việc cho phép bots crawl website là cần thiết để công cụ tìm kiếm có thể hiểu và cập nhật thông tin trên trang web.
Tuy nhiên, có những trường hợp khi chủ sở hữu trang không muốn bots crawl website của họ. Điều này có thể là vì lý do bảo mật, không muốn công khai thông tin, hoặc vì lo ngại về việc bot crawl website có thể gây ra tình trạng quá tải máy chủ.
Quản lý bot quan trọng như thế nào đến việc thu thập dữ liệu website
Quản lý bót (bot management) đóng vai trò quan trọng trong việc đảm bảo việc crawl website diễn ra hiệu quả và bảo vệ trang web khỏi những vấn đề liên quan đến bảo mật và tải trọng máy chủ.
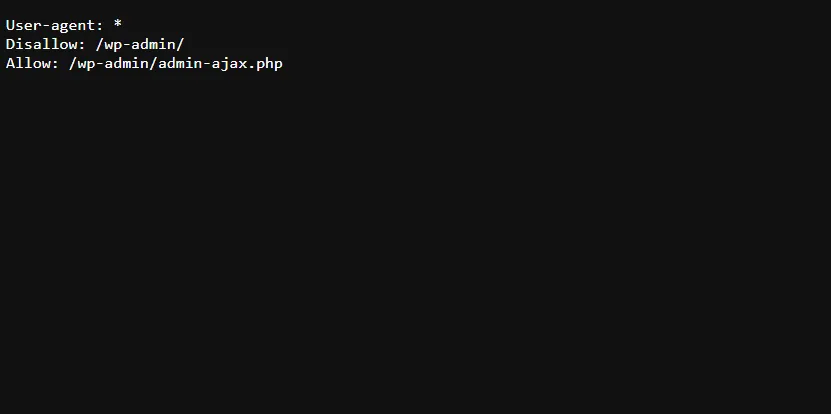
Việc không quản lý bót đúng cách có thể dẫn đến hiện tượng crawl lặp đi lặp lại, gây ra sự cố liên quan đến bảo mật, và làm giảm hiệu suất trang web.
Một số cách quản lý bót bao gồm:
- Thiết lập tệp robots.txt: Tệp robots.txt được sử dụng để chỉ định cho bót các trang web nào nên hay không nên crawl. Nó giúp hạn chế việc crawl vào các trang không cần thiết và bảo vệ dữ liệu nhạy cảm.
- Thiết lập giới hạn tốc độ crawl: Để tránh quá tải máy chủ, chủ sở hữu trang web có thể thiết lập giới hạn tốc độ crawl cho bots. Điều này giúp điều chỉnh tốc độ crawl sao cho phù hợp với hiệu suất máy chủ.
- Xác định User-Agent: Xác định và kiểm soát các User-Agent của bots giúp phân biệt bots của các công cụ tìm kiếm với bots của các công ty khác.
So sánh Web Scraping và Web Crawling
Khi nói đến việc thu thập thông tin trên Internet, hai khái niệm phổ biến là Web Scraping và Web Crawling. Dù có nhiều điểm tương đồng, nhưng chúng khác nhau về mục đích và phạm vi hoạt động.
Web Scraping
Web Scraping là quá trình tự động thu thập thông tin từ trang web và lưu trữ dữ liệu vào một cơ sở dữ liệu hoặc tệp tin. Điều này giúp trích xuất các dữ liệu cụ thể mà người dùng quan tâm từ một trang web.
Web Scraping thường được sử dụng để thu thập dữ liệu có cấu trúc từ các trang web, chẳng hạn như giá sản phẩm từ các trang thương mại điện tử, thông tin công ty từ trang web doanh nghiệp, và nhiều thông tin khác.
Web Crawling
Web Crawling, như đã đề cập ở phần trước, là quá trình tự động duyệt qua các trang web trên Internet để thu thập thông tin. Điều này giúp cập nhật dữ liệu của công cụ tìm kiếm và đảm bảo kết quả tìm kiếm chính xác cho người dùng.

Web Crawling không chỉ tập trung vào việc thu thập dữ liệu cụ thể như Web Scraping, mà thay vào đó, nó giúp xác định và lưu trữ thông tin toàn diện từ các trang web.
Các loại Web Crawler hoạt động trên Internet
Có nhiều công cụ tìm kiếm phổ biến trên Internet, và mỗi công cụ này sử dụng các loại Web Crawler riêng biệt để thu thập dữ liệu từ các trang web. Dưới đây là một số công cụ tìm kiếm phổ biến và loại Web Crawler mà chúng sử dụng:
Google sử dụng một loạt Web Crawler có tên gọi là Googlebot để crawl và lưu trữ thông tin từ hàng tỷ trang web. Googlebot giúp công cụ tìm kiếm của Google cập nhật kết quả tìm kiếm liên tục và đảm bảo độ chính xác cao cho người dùng.

Bing
Bing sử dụng Bingbot để crawl các trang web và thu thập thông tin. Bingbot giúp Bing cập nhật dữ liệu và hiển thị kết quả tìm kiếm đa dạng và chất lượng cho người dùng.
Yandex
Yandex sử dụng Yandexbot để thu thập thông tin từ các trang web. Yandexbot đảm bảo rằng các kết quả tìm kiếm của Yandex là đáng tin cậy và đáp ứng nhu cầu của người dùng tại khu vực Nga và CIS.

Baidu
Baidu, công cụ tìm kiếm phổ biến ở Trung Quốc, sử dụng Baiduspider để crawl các trang web. Baiduspider giúp Baidu cung cấp kết quả tìm kiếm chính xác cho người dùng Trung Quốc và quốc tế.
Hướng dẫn xây dựng một web crawler đơn giản
Xây dựng một web crawler đơn giản có thể giúp bạn thu thập thông tin từ các trang web một cách nhanh chóng và hiệu quả. Dưới đây là một hướng dẫn đơn giản để bạn có thể bắt đầu:
- Xác định mục tiêu: Xác định mục tiêu của web crawler của bạn. Bạn muốn thu thập thông tin từ các trang web cụ thể nào và dùng thông tin đó cho mục đích gì?
- Chọn ngôn ngữ lập trình: Chọn ngôn ngữ lập trình phù hợp để xây dựng web crawler. Python và Node.js thường được sử dụng phổ biến cho công việc này.
- Sử dụng thư viện và framework: Sử dụng các thư viện và framework phổ biến như Scrapy (Python) hoặc Cheerio (Node.js) để giúp bạn dễ dàng crawl dữ liệu từ các trang web.
- Xác định User-Agent: Xác định User-Agent cho web crawler của bạn để bot được nhận dạng và chấp nhận bởi trang web.
- Xác định tệp robots.txt: Trước khi crawl một trang web, hãy kiểm tra tệp robots.txt của trang web đó để đảm bảo bot của bạn được phép truy cập các trang.
- Xác định độ trễ: Xác định thời gian độ trễ giữa các lần truy cập vào các trang web để tránh quá tải máy chủ.
- Lưu trữ dữ liệu: Lưu trữ dữ liệu thu thập được vào cơ sở dữ liệu hoặc tệp tin để bạn có thể sử dụng sau này.
- Kiểm tra lại độ chính xác: Đảm bảo kiểm tra lại độ chính xác của dữ liệu thu thập được để đảm bảo nó đáp ứng mục tiêu ban đầu của bạn.
Xây dựng một web crawler đơn giản có thể là một công việc thú vị và bổ ích. Tuy nhiên, hãy nhớ tuân thủ chính sách của các trang web mà bạn crawl và luôn lưu ý rằng việc crawl website có thể tạo ra tải trọng cho máy chủ của trang web đó.
Lời kết
Hy vọng bài viết này đã giúp bạn hiểu rõ hơn về Crawl là gì và cách bot của công cụ tìm kiếm crawl website. Hãy tiếp tục nghiên cứu và cải thiện hiểu biết về SEO để tối ưu hóa trang web của bạn và cải thiện vị trí trên các công cụ tìm kiếm. Cảm ơn đã theo dõi bài viết của Checknet.